
tg-me.com/knowledge_accumulator/235
Last Update:
Recommender Systems with Generative Retrieval [2023] - наконец-то генеративные рекомендации?
Нечасто пишу сюда про статьи по рекомендациям - обычно в них мало интересного, но иногда мне попадается что-нибудь стоящее.
Итак, часто, если у вас есть мощная рекомендательная модель типа трансформера, то она получает на вход пару (юзер, документ) в каком-нибудь виде и предсказывает таргеты - лайки / покупки / другие. Таким образом, одно применение модели позволяет оценить качество одного кандидата.
Такую штуку нельзя прогнать для каждого документа в базе, и поэтому существуют предыдущие стадии ранжирования, работающие более тупым образом - например, у нас есть вектор пользователя, и мы пытаемся быстро найти несколько тысяч ближайших к нему документов-соседей.
Но к этому можно подойти и с другой стороны. Пусть каждый документ представлен вектором. Может ли какая-нибудь мощная модель гененировать вектор? Напрямую делать это нельзя - mse-лоссы вроде как плохо работают в таком сетапе.
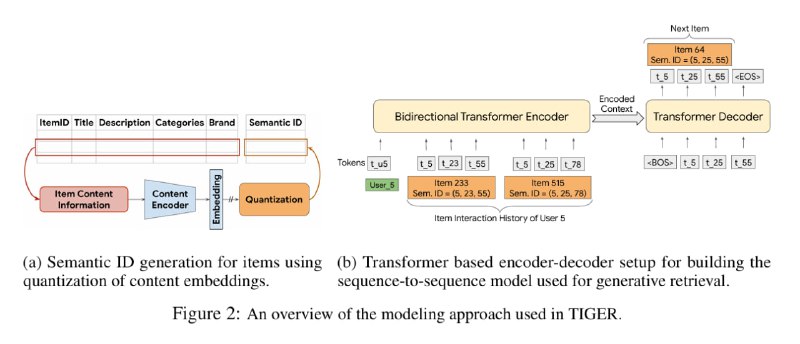
В статье предлагают перейти к трансформерному декодеру. Чтобы дискретизовать эмбеддинги, нужно обучить что-то типа VQ-VAE, который умеет превращать эмбеддинг в небольшую последовательность дискретных чисел. Таким образом, данные становятся похожими на язык.
Вкратце о VQ-VAE - вместо того, чтобы обучать скрытое представление малой размерности, мы обучаем N эмбеддингов - сodebook. Получая входной вектор, мы находим ближайший к нему в таблице, его индекс и будет скрытым представлением. Декодированием будет просто взятие нужного вектора из сodebook. Это всё, конечно, недифференцируемо, но на такой случай есть старый добрый метод - забить хер и использовать Straight Through Estimator.
В статье используют RQ-VAE - много codebook-ов, после каждого из которых мы вычитаем из входа ближайший вектор из codebook-а и затем подаём в следующий. Таким образом, каждый айтем они кодируют набором из K чисел. Утверждается, что проблемы с декодированием набора чисел в номер документа несущественны.
Также там сравнивают с более простым методом дискретизации эмбеддингов. Согласно нему, мы проводим случайные гиперплоскости в пространстве эмбеддингов и записываем, с какой стороны от каждой из них оказался айтем. Получившиеся N бит - это и есть новый номер айтема. Метод в 100 раз проще, но по результатам хуже.
У нас с коллегами возникли вопросы по применению всей этой системы в реальном мире. Главный из них - что делать, если векторные представления айтемов меняются со временем? Переобучая / дообучая RQ-VAE на ходу, нам нужно пересоздавать все дискретные представления айтемов, и каждый раз заново перестраивать весь датасет. А это фу.
Лично я пока не решусь ставить на этот подход и заниматься внедрением у себя, однако, направление генеративных рекомендаций могут оказаться перспективными в долгосрочной перспективе.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/235